What is Machine learning?
How do we tell a computer what a cat is. Lets say we are asked to write a code to detect if a particular picture is cat or not. How do you do that?
The goal of ML is to make machines act more and more like humans because the smarter they get, they help us achieve our goals easily
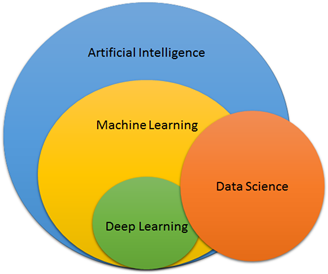
AI vs ML vs DL vs DS
- Artificial Intelligence: A machine intelligence that acts like a human
- Detecting heart disease from images
- Machine Learning: ML is a subset of an AI. Its an approach to try and achieve AI through systems that can find patterns in a set of data. According to Stanford, ML is the science of getting computers to act without being explicitly programmed.
- Deep Learning: Deep learning or Deep Neural Networks is just one of the techniques for implementing ML.
- Data Science: Often the role of Data Science and ML expert are quite overlapping. Field of DS simply means analyzing data, looking at data and then doing something with it, usually some sort of business goal.If you are a Data scientist you need to know ML. If you are an ML expert you need to know DS. You cant do one without the other.
Types of ML
ML is simply about predicting results based on incoming data. Some of the machine learning categories we often see…
- Supervised learning : The data that we recieve already has categories[ labeled data and test data].
- ML algorithm tries to use the data to predict a label if it guesses the label wrong, the algo corrects itself and tries again. coz of This active correction its called supervised learning
- Classification : The goal is to predict discrete values, e.g. {1,0}, {True, False}, {spam, not spam}.
- binary classification -> only 2 options
- multi-classification -> more than 2 options
- Regression : The goal is to predict continuous values, e.g. home prices.
- Eg: Predicting stock prices, Hire engineers based on experience or age or where they live [inputs that are labeled]
- Supervised learning algorithms try to model relationships and dependencies between the target prediction output and the input features such that we can predict the output values for new data based on those relationships which it learned from the previous data sets.
- List of Common Algorithms:
- Nearest Neighbor
- Naive Bayes
- Decision Trees
- Linear Regression
- Support Vector Machines (SVM)
- Neural Networks
- Unsupervised learning : Data without labels. Think of it as csv files without column names labeled
- Clustering : Based on given data, machine identifies different groups.
- Association rule learning : We associate different things to predict what customer might buy in the future.
- Unsupervised learning algorithms are mainly used in pattern detection and descriptive modeling. These algorithms try to use techniques on the input data to mine for rules, detect patterns, and summarize and group the data points
- Eg: Recommendation systems.
- List of Common Algorithms:
- k-means clustering, Association Rules
- Transfer learning TL leverages what one machine learning model has learned in another ML model
- Semi-supervised learning: In previous two types one has labeled data and the other has none. Semi-supervised learning falls in between these two.
- Reinforcement learning: Teaching machines through trial and error.It allows machines and software agents to automatically determine the ideal behavior within a specific context, in order to maximize its performance.
- Reinforcement learning algorithm called the agent continuously learns from the environment in an iterative fashion. In the process, the agent learns from its experiences of the environment until it explores the full range of possible states.
- A program simply learns a game by playing it millions of times until it gets the highest score.
- List of Common Algorithms:
- Q-Learning
- Temporal Difference (TD)
- Deep Adversarial Networks
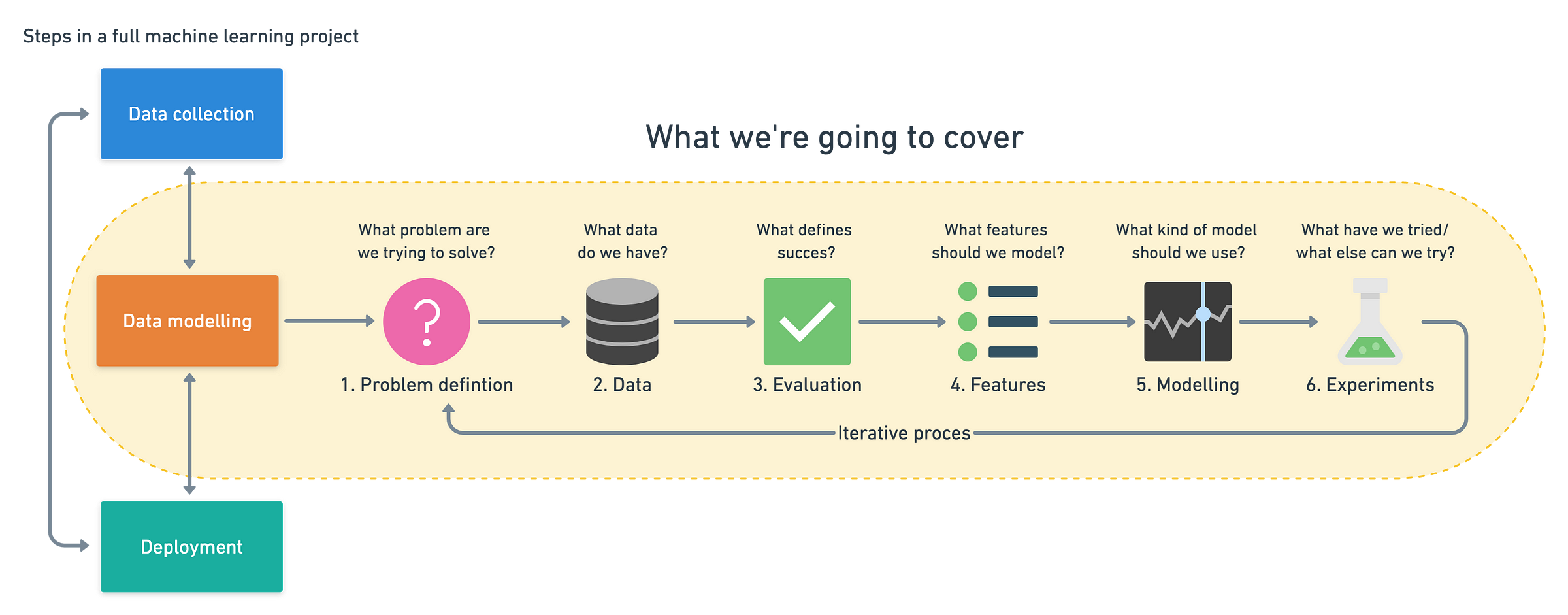
6 Step Machine Learning Framework
- Problem definition: what problem are we solving?. Is it supervised or unsupervised. Is it classification or regression?
- Data: what kind of data do we have? Different kinds of data..
- Structured data (spreadsheets), unstructured data(audio or image)
- Evaluation: what defines success for us? There are no 100% perfect models. Instead we begin by saying for so and so project to be feasible we need atleast 95% accurate model.
- Types of metrics:
- Classification : Accuracy, precision, recall
- Regression : Mean absolute error (MAE), Mean Squared Error(MSE), Root Mean Squared Error(RMSE)
- Recommendation problems : precision at K
- Types of metrics:
- Features: What do we already know about data?
- Features refers to what kind of data do we have in structured and unstructured data.
- Eg: to predict whether or not someone has a heart disease we might use their body weight as a feature, since body weight is a number. Its called Numerical feature. If someone’s body is over a certain number, they are more likely to have a heart disease. There are other features as well like categorical (A person is of which gender) and derived -> creates new feature using the existing ones.(Did a person visit hospital last year)
- Feature Engineering : Looking at different features of data and creating new ones/altering existing ones.
- Feature Coverage: The process of ensuring all samples have similar information is called feature coverage. In an ideal dataset we get complete feature coverage (atleast 10% coverage should be there)
- ML algos goal is to make the patterns out of known data to make predictions
- Modelling: (splitting data) Based on our problem and data, what model should we use?. Figure out right model for right kind of problem
- 3 parts to modelling
- Choosing a training model
- Tuning a model
- Model Comparision
- 3 parts to modelling
- Experimentation: How could we improve/what can we try next?
 Image
Full version on whimsical
Image
Full version on whimsical
Modelling data - Splitting data
The most important concept in ML ( The training, validation and test sets or 3sets )
Data is split into 3 parts
Training : Train your model on this with Training split (70-80%)
Validation: Tune your model on this with validation split (10-15%)
Test : Test and compare on this with test split (10-15%)
Generalization: The ability for an ML model to perform well on a data it hasnt seen before, because of what its learned on another dataset.
Modelling data - Choosing the model
- Based on our problem and data what model should we choose?
- Once you got your data into training, validation and testing. One can start to go through each of these steps.
choose a model and train your data
- If you are working with structured data : gradient boosting algorithms like CatBoost and XGBoost, decision trees such as random forest
- If you are working with unstructured data : deep learning, transfer learning and neural networks tend to work best
- Once a model is chosen train your data. Main goal is to line up inputs and outputs
- Depending on how much data we have and how complex our model is training may take a while. GOAL: Minimise the time between experiments (generally neural networks take more time to get trained)
Modelling data - Tuning a model
Based on our problem and data what model should we choose?
Model can be tuned for different types of data. Like how a car can be tuned for different race tracks or different surfaces.
Depending on whar kind of model we’re using will depend on what kind of hyper properties you can choose.
- Eg: Random forest will allow you to adjust number of trees. A neural network will allow you to choose number of layers
Things to remember: ML models have hyper parameters one can adjust. A model’s first results aren’t its last. Tuning can take place on training or validation data sets.
Modelling data - Comparison
- How will our model perform in the real world?
- After tuning and improving model’s performance through hyper parameters its time to see how it performs on the tests for ML model
Overfitting and underfitting
- Poor performance on training data means the model hasn’t learned properly and is underfitting. Try a different model, improve the existing one through hyperparameter or collect more data.
- Great performance on the training data but poor performance on test data means your model doesn’t generalize well. Your model may be overfitting the training data. Try using a simpler model or making sure your the test data is of the same style your model is training on.
- Another form of overfitting can come in the form of better performance on test data than training data. This may mean your testing data is leaking into your training data (incorrect data splits) or you’ve spent too much time optimizing your model for the test set data. Ensure your training and test datasets are kept separate at all times and avoid optimizing a models performance on the test set (use the training and validation sets for model improvement. testing and model comparision on test dataset).
- Data mismatch happens when the data you’re testing on is different from the data you’re training(such as having different test features on training data and test data). Ensure training is done on same kind of data as we are testing.
- Poor performance once deployed (in the real world) means there’s a difference in what you trained and tested your model on and what is actually happening. Ensure the data you’re using during experimentation matches up with the data you’re using in production.
- The ideal model shows up in Goldilocks zone(balanced model) . It just right fits in not too well but not too poorly.
Fixes for overfitting and underfitting
- Underfitting:
- Try a more advanced model
- Increase model hyperparameters
- Reduce amount of features
- Train longer
- Overfitting:
- Collect more data
- try a less advanced model
Things to remember: Avoid overfitting and underfitting(head towards generality). Keep the tests seperate at all costs. Compare apples to apples (Make sure 2 models you are comparing have been created in same sort of environment). One best performance metric does not equal best model
6 step field guide for ML Projects
Other resources:
Experiment with tools: